
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- c++공부
- 영상처리
- c++
- 컴퓨터 비전
- matlab 영상처리
- 팀프로젝트
- c언어 정리
- c언어
- C언어 공부
- 골빈해커
- 케라스 정리
- 모두의 딥러닝 예제
- 파이토치 김성훈 교수님 강의 정리
- 미디언 필터링
- 모두의 딥러닝
- MFC 프로그래밍
- 딥러닝 공부
- pytorch zero to all
- 딥러닝 스터디
- object detection
- 파이토치
- 파이토치 강의 정리
- tensorflow 예제
- Pytorch Lecture
- 김성훈 교수님 PyTorch
- pytorch
- 가우시안 필터링
- TensorFlow
- 딥러닝
- 해리스 코너 검출
Archives
- Today
- Total
ComputerVision Jack
MicroNet: Towards Image Recognition with Extremely Low FLOPs 본문
Reading Paper/Classification Networks
MicroNet: Towards Image Recognition with Extremely Low FLOPs
JackYoon 2022. 1. 17. 13:02반응형
MicroNet: Towards Image Recognition with Extremely Low FLOPs
Abstract
- 저자들은 MicroNet 매우 낮은 연산을 사용하여 ****효율적인 Convolution Neural Network 제시한다.
- 저자들은 2가지 원칙에 입각하여 Low
Flops다룬다.(b) 복잡한Non-linearity Layer마다 사용하여, NetworkDepth에 대한 보상으로 작동시킨다. - (a)
Node Connectivity낮춤으로써, Network의Width줄이는 방향을 피한다. - 첫 번째로 Micro-Factorized Convolution 제안하여
PointwiseandDepthwiseConvolution 연산에 대해 낮은 차원으로 분해하여 Channels 수와 Input/Output Connectivity에 좋은Trade-off생성한다. - 두 번째로 Dynamic Shift-Max 새로운 Activation Function 제안한다. 이 함수는 Input Feature-map과 그것의 Channel 방향으로 순회된 Feature-map 사이의
Dynamic Fusions의Non-linearity향상한다. - Fusions는 Input에 대해 Parameters가 적응되어 갈 때 마다 동적으로 변화한다.
Introduction
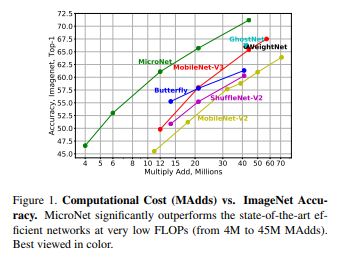
- 최근, CNN Architectures 효율적으로 설계하는 연구가 진행되고 있다. 이러한 연구는 Edge device에서 높은 질의 서비스가 가능하게 만들었다.
- 해당 논문에서 MobileNetv3 보다 절반의 예산을 갖고 Image Classification(1000 classes)에 도전하기로 했으며 Resolution은 224 x 224 이고 이를
6MFpos아래로 진행하는 것이다. - 매우 낮은 연산을 진행하는 방식은 모든 Layer 설계함에 있어서 주의를 필요로 한다. 이러한 낮은 예산에 집중하여 MobileNet과 ShuffleNet은 Network의
Width와Depth줄이는 방식으로 접근하는데, 이는 성능 측면의 감소를 불러온다. - 저자는 Pointwise와 Depthwise Convolution에 대해 저 차원으로 Micro-Factorized Convolution 적용한다. 이는 Input/Output Connectivity와 Channels 사이의 균형을 제공한다.
- Pointwise Convolution에 대해
Group-Adaptive Convolution적용하고, Depthwise Convolution에 대해 k x k (kernel)에 대해1 x kork x 1적용한다. - 다른 단계에서 적합한 결합은 Channels 희생 없이 연산 비용을 절감 시킨 다는 것을 보여준다.
- 2가지 측면에 대해
Non-linearity향상 하는 Dynamic Shift-Max 새로운 Activation Function 제안한다.(b) Input에 대해 Parameter가 정해지면 이러한 Fusions 동적이다. - (a) Input Feature-map과 Circular Channel Shift 사이 Multiple Fusions 최대화 한다.
Our Method: MicroNet
Design Principles
- Low FLOPs 접근은 Network의
Width(number of channels)와Depth(number of layers) 제한한다. Graph 관점에서 저자는Connectivity에 대해 output node의 연결 수로 정의한다. - 따라서 연결 수는 output의 channels과 connectivity 수와 같다.
- Computation cost 고정되어 있다면, 이러한 Channel 수는 Connectivity와 마찰이 생긴다. 따라서 그들 간의 좋은 균형은 Channel 감소를 피하고 Layer Feature 향상 시킨다고 믿는다.
- 그러므로 Circumventing the reduction of network width through lowering node connectivity 원칙이 등장한다.
- Network 줄이는 관점에서 Depth는 중요하다. ReLU와 같은 활성화 함수를 Encode 시킬 때 성능 저하를 발생할 수 있다.
- 따라서 Compensating for the reduction of network depth by improving non-linearity per layer 원칙이 등장한다.

Micro-Fatorized Convolution
- 저자는 Pointwise와 Depthwise Convolution
finer scale분해한다. 이 목적은 Channels 수와 Input/Output Connectivity 사이의 균형을 위하는 것이다.
Micro-Factorize Pointwise Convolution :
- Pointwise Convolution에 대해 Group-Adaptive Convolution 분해할 것을 제안한다. Convolution kernel
W값을 Input/Output Channels와 같게 추정한다. - kernel marix
W2개의 Group-Adaptive Convolution 분해되며, 각각의 GroupG는 ChannelsC에 달려있다.
$W = PΦQ^T \quad \quad G = \sqrt{C/R}$

Micro-Factorized Depthwise Convolution :
k x kDepthwise Convolution에 대해k x 1kernel,1 x kkernel 진행한다. 이는 Micro-Factorized Pointwise Convolution과 같은 수학적 양식을 공유한다.
Combining Miro-Factorized Pointwise and Depthwise Convolutions :
(a) Regualr Combination
(b) Lite Combination
- 2 가지 방법으로 결합한다. 전자는 2 Convolution에 대해 Concat 진행하고, 후자는 Channels 확장하여 Channels 공간적 방향에 연산을 진행한다.
- Lite Combination의 경우 더 Low Level에서 효과적이며 더 많은 Channels Fusion 담을 수 있다.
Dynamic Shift-Max
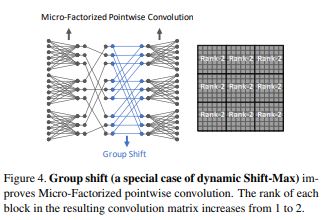
- Dynamic Shift-Max는 Group 간의 연결을 강화 시킬 수 있다. 이는
Group간의 연결에 집중한 Micro-Factorized Pointwise Convolution 통해 완성된다.
Non-Linearity
- Dynamic Shift Max 2가지
Non-Linearity통해 만들어 질 수 있다.(b) Parameter(x)는 input(x)에 대한 Function - (a) J Groups에 K Different 만큼 Output 극대화
- 이러한 방식은 Layer 수를 줄이는 방법에 대한 강한 보상을 제공한다.
Connectivity
- Dynamic Shift Max는 Channel Group 간의 연결을 향상 시킨다.
Computational Complexity
- 연산의 복잡한 정도는 3가지로 구분된다.(b) Generating Parameter
- (c) Apply Dynamic Shift-Max per Channels
- (a) Average Pooling
Relation to Prior Work
- MicroNet은 MobileNet과 ShuffleNet에 대해 Convolution과 Activation이 다르다.
- Pointwise Convolution 관해 Group-Adaptive Convolution 나누고, 여기서
G는 위의 수식을 따른다. 그리고 Depthwise Convolution 적용하고 Channel Connectivity 고려한 Activation 적용한다.
MicroNet Architecture
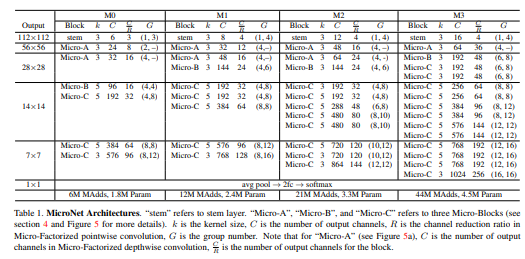
- MicroNet은 3가지 Type의
Micro-Blocks사용하며 모두Dynamic-Shift MaxActivation 함수를 사용한다.
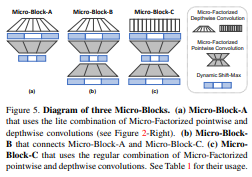
Micro-Block-A
- Micro-Block-A의 경우 Micro-Factorized Pointwise와 Depthwise Convolution의 Lite Combination이루어져 있다.
Micro-Block-B
- Micro-Block-B는 Block-A와 Block-C 연결하는데 사용된다. A와 다른 점은 2가지 Group-Adaptive Convolution 포함한다는 것이다.
- 전자는
Channel Squeeze하고 후자는Channel Expand한다. Micro-Block-B 경우 MicroNet 당 한번만 사용된다.
Micro-Block-C
- Micro-Factorized Depthwise와 Pointwise Convolution에 대해
Concate결합하는 Block 이다. - 만약 Dimension이 맞지 않는 다면
Skip Connection사용한다.
Conclusion
- 낮은 연산 비용을 갖는 MicroNet 소개한다.
- MicroNet은 Micro-Factorized Convolution과 Dynamic Shift-Max 기반으로 제작된다.
from ..layers.convolution import Conv2dBnAct, Conv2dBn, DepthwiseConvBnAct
from ..layers.convolution import DepthSepConvBnAct
from ..layers.blocks import MicroBlockA, MicroBlockB, MicroBlockC
from ..layers.activation import DynamicSiftMax
from ..initialize import weight_initialize
import torch
from torch import nn
# Spatial Separable Convolution
class MicroNetStem(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=2):
super(MicroNetStem, self).__init__()
self.conv = Conv2dBnAct(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=2)
def forward(self, input):
output = self.conv(input)
return output
class Make_Layers(nn.Module):
def __init__(self, layers_configs):
super(Make_Layers, self).__init__()
self.layers_configs = layers_configs
self.layer = self.microBlock(self.layers_configs)
def forward(self, input):
return self.layer(input)
def microBlock(self, layers_configs):
layers = []
for b, i, k, o, r, g, s in layers_configs:
if b == 'a':
layers.append(MicroBlockA(in_channels=i, kernel_size=k, out_channels=o, ratio=r, group=g, stride=s, act='DyShMax'))
elif b == 'b':
layers.append(MicroBlockB(in_channels=i, kernel_size=k, out_channels=o, ratio=r, group=g, stride=s, act='DyShMax'))
else:
layers.append(MicroBlockC(in_channels=i, kernel_size=k, out_channels=o, ratio=r, group=g, stride=s, act='DyShMax'))
return nn.Sequential(*layers)
class MicroBlockA(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, ratio, group, stride, act=None):
super(MicroBlockA, self).__init__()
self.depthwise = DepthSepConvBnAct(in_channels=in_channels, expand=out_channels, kernel_size=kernel_size, stride=stride, act=act)
self.pointwise = Conv2dBnAct(in_channels=self.depthwise.get_channels(), out_channels=out_channels//ratio, kernel_size=1, stride=1, dilation=1,
groups=group[0], padding_mode='zeros', act=DynamicSiftMax(in_channels=self.depthwise.get_channels(), out_channels=out_channels//ratio))
def forward(self, input):
output = self.depthwise(input)
output = self.pointwise(output)
return output
class MicroBlockB(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, ratio, group, stride, act=None):
super(MicroBlockB, self).__init__()
self.depthwise = DepthSepConvBnAct(in_channels=in_channels, expand=out_channels, kernel_size=kernel_size, stride=stride, act=act)
self.pointwise1 = Conv2dBnAct(in_channels=self.depthwise.get_channels(), out_channels=out_channels//ratio, kernel_size=1, stride=1, dilation=1,
groups=group[0], padding_mode='zeros', act=act)
self.pointwise2 = Conv2dBnAct(in_channels=out_channels//ratio, out_channels=out_channels, kernel_size=1, stride=1, dilation=1,
groups=group[1], padding_mode='zeros', act=act)
def forward(self, input):
output = self.depthwise(input)
output = self.pointwise1(output)
output = self.pointwise2(output)
return output
class MicroBlockC(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, ratio, group, stride, act=None):
super(MicroBlockC, self).__init__()
self.out_channels = out_channels // ratio
self.depthwise = DepthwiseConvBnAct(in_channels=in_channels, kernel_size=kernel_size, stride=stride, dilation=1,
padding_mode='zeros', act=nn.ReLU6())
self.pointwise1 = Conv2dBnAct(in_channels=in_channels, out_channels=out_channels//ratio, kernel_size=1, stride=1, dilation=1,
groups=group[0], padding_mode='zeros', act=DynamicSiftMax(in_channels=in_channels, out_channels=out_channels//ratio))
self.pointwise2 = Conv2dBnAct(in_channels=out_channels//ratio, out_channels=out_channels, kernel_size=1, stride=1, dilation=1,
groups=group[1], padding_mode='zeros', act=DynamicSiftMax(in_channels=in_channels, out_channels=out_channels//ratio))
self.identity = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride)
def forward(self, input):
output = self.depthwise(input)
output = self.pointwise1(output)
output = self.pointwise2(output)
if input.size() != output.size():
input = self.identity(input)
output = output + input
return output
class _MicroNet_M0(nn.Module):
def __init__(self, in_channels, classes):
super(_MicroNet_M0, self).__init__()
self.micronetStem = MicroNetStem(in_channels, out_channels=6)
# configs = block_type, in_channels, kernel_size, out_channels, Reduction_ratio, Group, stride
layer1 = [['a', 6, 3, 24, 3, (2, 0), 2]]
layer2 = [['a', 8, 3, 32, 2, (4, 0), 2]]
layer3 = [['b', 16, 5, 96, 6, (4, 4), 2], ['c', 96, 5, 192, 6, (4, 8), 1]]
layer4 = [['c', 192, 5, 384, 6, (8, 8), 2], ['c', 384, 5, 576, 6, (8, 12), 1]]
self.layer1 = Make_Layers(layer1)
self.layer2 = Make_Layers(layer2)
self.layer3 = Make_Layers(layer3)
self.layer4 = Make_Layers(layer4)
self.classification = nn.Sequential(
Conv2dBnAct(in_channels=576, out_channels=1280, kernel_size=1),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(1280, classes, 1)
)
def forward(self, input):
stem = self.micronetStem(input)
s1 = self.layer1(stem)
s2 = self.layer2(s1)
s3 = self.layer3(s2)
s4 = self.layer4(s3)
pred = self.classification(s4)
b, c, _, _ = pred.size()
pred = pred.view(b, c)
return {'pred':pred}
def MicroNet(in_channels, classes=1000, varient=0):
if varient == 0:
model = _MicroNet_M0(in_channels, classes=classes)
elif varient == 1:
pass
pass
else:
pass
weight_initialize(model)
return model
if __name__ == '__main__':
model = MicroNet(in_channels=3, classes=1000, varient=0)
model(torch.rand(1, 3, 224, 224))반응형
'Reading Paper > Classification Networks' 카테고리의 다른 글
| An Energy and GPU-Computation Efficient Backbone Network fro Real-Time Object Detection (0) | 2022.01.24 |
|---|---|
| FrostNet: Towards Quantization-Aware Network Architecture Search (0) | 2022.01.20 |
| MnasNet: Platform-Aware Neural Architectures Search for Mobile (0) | 2022.01.13 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2022.01.04 |
| Designing Network Design Spaces (0) | 2022.01.03 |
'Reading Paper/Classification Networks' Related Articles
more




Comments