
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 딥러닝
- matlab 영상처리
- 해리스 코너 검출
- pytorch zero to all
- 파이토치 김성훈 교수님 강의 정리
- 가우시안 필터링
- c++공부
- c언어 정리
- tensorflow 예제
- 파이토치 강의 정리
- c언어
- 팀프로젝트
- c++
- pytorch
- TensorFlow
- C언어 공부
- 케라스 정리
- 모두의 딥러닝
- object detection
- 파이토치
- 김성훈 교수님 PyTorch
- Pytorch Lecture
- 영상처리
- MFC 프로그래밍
- 모두의 딥러닝 예제
- 딥러닝 공부
- 딥러닝 스터디
- 골빈해커
- 미디언 필터링
- 컴퓨터 비전
Archives
- Today
- Total
ComputerVision Jack
MnasNet: Platform-Aware Neural Architectures Search for Mobile 본문
Reading Paper/Classification Networks
MnasNet: Platform-Aware Neural Architectures Search for Mobile
JackYoon 2022. 1. 13. 15:59반응형
MnasNet: Platform-Aware Neural Architecture Search for Mobile
Abstract
- Mobile CNNs의 모든
Dimension설계와 향상을 위한 많은 노력들이 진행되어 왔지만, 많은 Architecture 고려 될 수 있기 때문에Trade-off사이의 균형을 맞추긴 어렵다. - 해당 논문에서 모델의 Latency에 목적을 맞춘 mobile neural architecture search (MNAS) 접근을 통해
Accuracy와Latency간의 좋은 Trade-off 균형을 갖는 모델을 찾는다. - 따라서 Network 전반적으로 Layer의 다양성을 장려하는 새로운 Factorized Hierarchical Search Space 제안한다. (= MNasNet)
Introduction

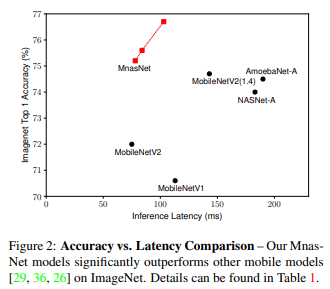
- 현대 CNNs 모델은 깊어지고 넓어지고 있다. 그렇기 때문에 느려지고 더 많은 연산을 필요로 한다. 하지만 연산에 대한 증가는 자원 제한 적인
mobile및embedded device환경에서 최고 성능을 가져오긴 어렵다. - Mobile CNNs 향상 하기 위해 Network의
Depth줄이거나Depthwise Convolution및Group Convolution적용하는 경우가 있었다. - 논문에선 automated neural architecture search 사용하여 Mobile CNNs 설계하는 방법을 제안한다. 해당 접근은 2 가지 핵심 아이디어에 기반을 두고 있다.
- 첫 번째로
Accuracy와Latency둘 다 최적화 하는 관점에서 설계 문제를 공식화 한다. 이 생각은FLOPs가 종종 부정확한 지표가 된다는 점에 영감을 받았다. - 두 번째로 이전에 automated approaches 탐색한
cell관찰하고 반복하여 같은 cell 쌓아서Network구성한다. 이를 통해 새로운 Factorized Hierarchical Search Space 제안한다. Layer의 계층 구조는 다르지만flexiblity와search space사이의 균형을 이루어야 한다.
- Multi-Objective Neural Architecture serach (MNAS) 도입하여 mobile device 환경에서 accuracy와 latency 최적화 한다.
- 새로운 Factorized hierarchical search space 제안하고 Layer 다양성을 가능하게 하고 flexibility와 search space size 균형을 만든다.
- ImageNet과 COCO Object Detection에서 새로운 SOTA 만들었다.
Problem Formulation

- multi-objective search 관점으로 설계 문제를 공식화 하였다. 이를 통해 높은 정확도를 갖고 추론 시간이 적은 CNN 모델을 찾는 것을 목표로 한다.

- 주어진 수식에서
m은 Model 이고 ,ACC(m)은 목적에 맞는 정확도를 지칭한다.LAT(m)은 지정된 mobile platform에서 추론 시간을 나타낸다. 그리고T는 목적의 추론 시간이다. - 하지만 위와 같은 접근은 단일 Metric에서 극대화 되며 multiple Pareto-optimal Solution 제공하진 않는다.
- 따라서 Architecture의 수행 연산에 대한 연구를 통해 단일 Architecture에서 multiple Pareto -optimal solution 발견하려고 노력했다.

Mobile Neural Architecture Search
- 이번 Section에선 새로운
Factorized Hierarchical Search Space에 대해 논의하고, Search Algorithm의 기반인Reinforcement-learning요약해보려고 한다.
Factorized Hierarchical Search Space

- 대부분 이전의 Search Space에 대한 연구는 복잡한
cell에 대한 연구가 아니라 반복하여 같은cell쌓는 관점으로 진행되었다. - 대조적으로, 저자는 고유
Blocks사용하여 새로운 Factorized Hierarchical Search Space 안에서 CNN 모델을 분해하였다. 따라서 다른Blocks사용되기 때문에 다른Layer Architectures갖는다. - 연산에 대한 제약 조건이 존재한다면, Kernel_size
K와 Filter_sizeN사이의 균형이 필요하다. Receptive Field에 큰 Kernel_size 적용 한다면 Filter_size 줄여서 대응해야 연산이 보존된다. - CNN 모델을 미리 정의한 Blocks 흐름으로 나누고 점진적으로 input resolution 줄이면서 CNN 모델의 Filter_size 늘려나갔다.
Convolutional ops: regular conv, depthwise conv, inverted bottleneck convConvolutional kernel size: 3 x 3, 5 x 5Squeeze-and-excitation ratio: 0, 0.25Skip ops: pooling, identity residualOutput filter size: FNumber of layers per block: N
Search Algorithm
- multi-objective search problem에 대해 Pareto optimal solution 찾으려 Reinforcement learning approach 사용하였다.
- Search Space 안으로 CNN 모델을
Tocken화 하여 리스트를 구축했다. 이러한 Token은 Reinforcement Learning의 Sequence에 의해 결정된다.
$J=E_p({a_1:T^Θ}) \quad[R(m)]$
Conclusion

- Reinforcement Learning 사용하여 Automated Neural Architecture Search 접근해 자원 제한적인 Mobile 환경에서 효율적인 구조를 찾는 방법을 제시한다.
- 논문의 핵심은 새로운 Factorized Hierarchical Search 과정을 통해 Mobile Model 찾고, Accuray와 Latency 사이 최고의 Tade-off 찾는 것이다.
import torch
from torch import nn
class MnasNetStem(nn.Module):
def __init__(self, in_channels, out_channels):
super(MnasNetStem, self).__init__()
self.conv = Conv2dBnAct(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=2)
def forward(self, input):
return self.conv(input)
class SepConv(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, stride):
super(SepConv, self).__init__()
self.dconv = DepthwiseConvBnAct(in_channels=in_channels, kernel_size=kernel_size, stride=stride)
self.conv = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
def forward(self, input):
output = self.dconv(input)
output = self.conv(output)
return output
class MBConv3(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, stride):
super(MBConv3, self).__init__()
self.conv1 = Conv2dBnAct(in_channels=in_channels, out_channels=in_channels, kernel_size=1)
self.dconv = DepthwiseConvBnAct(in_channels=in_channels, kernel_size=kernel_size, stride=stride)
self.se = SE_Block(in_channels=in_channels)
self.conv2 = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
self.identity = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride)
def forward(self, input):
output = self.conv1(input)
output = self.dconv(output)
output = self.se(output)
output = self.conv2(output)
if input.size() != output.size():
input = self.identity(input)
output = output + input
return output
class MBConv6(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, stride, act=None, SE=False):
super(MBConv6, self).__init__()
if act is None:
act == nn.ReLU()
else:
act = act
self.act = act
self.se=SE
self.conv1 = Conv2dBnAct(in_channels=in_channels, out_channels=in_channels, kernel_size=1, stride=1,
groups=1, padding_mode='zeros', act=self.act)
self.dconv = DepthwiseConvBnAct(in_channels=in_channels, kernel_size=kernel_size, stride=stride, dilation=1, padding_mode='zeros', act=self.act)
self.conv2 = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
self.se_block = SE_Block(in_channels=in_channels)
self.identity = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride)
def forward(self, input):
output = self.conv1(input)
output = self.dconv(output)
if self.se:
output = self.se_block(output)
output = self.conv2(output)
if input.size() != output.size():
input = self.identity(input)
output = output + input
return output
class Make_Layers(nn.Module):
def __init__(self, layers_configs):
super(Make_Layers, self).__init__()
self.layers_configs = layers_configs
self.layer = self.MBConv(self.layers_configs)
def forward(self, input):
return self.layer(input)
def MBConv(self, layers_configs):
layers = []
for b, i, k, o, s, in layers_configs:
if b == 0:
layers.append(SepConv(in_channels=i, kernel_size=k, out_channels=o, stride=s))
elif b == 3:
layers.append(MBConv3(in_channels=i, kernel_size=k, out_channels=o, stride=s))
elif b == 6:
layers.append(MBConv6(in_channels=i, kernel_size=k, out_channels=o, stride=s, act=None))
else:
layers.append(MBConv6(in_channels=i, kernel_size=k, out_channels=o, stride=s, act=None, SE=True))
return nn.Sequential(*layers)
class _MnasNet_A1(nn.Module):
def __init__(self, in_channels, classes):
super(_MnasNet_A1, self).__init__()
self.mnasnetStem = MnasNetStem(in_channels=in_channels, out_channels=32)
# Block_type, in_channels, kernel_size, out_channels, stride
layer1 = [[0, 32, 3, 16, 1], [6, 16, 3, 24, 2], [6, 24, 3, 24, 1]]
layer2 = [[3, 24, 5, 40, 2], [3, 40, 5, 40, 1], [3, 40, 5, 40, 1]]
layer3 = [[6, 40, 3, 80, 1], [6, 80, 3, 80, 1], [6, 80, 3, 80, 1],
[6, 80, 3, 80, 1], [62, 80, 3, 112, 2], [62, 112, 3, 112, 1]]
layer4 = [[62, 112, 5, 160, 2], [62, 160, 5, 160, 1], [62, 160, 5, 160, 1],
[6, 160, 3, 320, 1]]
self.layer1 = Make_Layers(layer1)
self.layer2 = Make_Layers(layer2)
self.layer3 = Make_Layers(layer3)
self.layer4 = Make_Layers(layer4)
self.classification = nn.Sequential(
Conv2dBnAct(in_channels=320, out_channels=1280, kernel_size=1),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(1280, classes, 1)
)
def forward(self, input):
stem = self.mnasnetStem(input)
s1 = self.layer1(stem)
s2 = self.layer2(s1)
s3 = self.layer3(s2)
s4 = self.layer4(s3)
pred = self.classification(s4)
b, c, _, _ = pred.size()
pred = pred.view(b, c)
return {'pred':pred}
def MnasNet(in_channels, classes=1000, varient=1):
if varient == 1:
model = _MnasNet_A1(in_channels=in_channels, classes=classes)
weight_initialize(model)
return model
if __name__ == '__main__':
model = MnasNet(in_channels=3, classes=1000, varient=1)
model(torch.rand(1, 3, 224, 224))반응형
'Reading Paper > Classification Networks' 카테고리의 다른 글
| FrostNet: Towards Quantization-Aware Network Architecture Search (0) | 2022.01.20 |
|---|---|
| MicroNet: Towards Image Recognition with Extremely Low FLOPs (0) | 2022.01.17 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2022.01.04 |
| Designing Network Design Spaces (0) | 2022.01.03 |
| GhostNet: More Features from Cheep Operations (0) | 2021.12.31 |
'Reading Paper/Classification Networks' Related Articles
more




Comments