
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 미디언 필터링
- c++공부
- 파이토치 김성훈 교수님 강의 정리
- 파이토치 강의 정리
- tensorflow 예제
- object detection
- 영상처리
- c++
- matlab 영상처리
- 팀프로젝트
- pytorch zero to all
- 컴퓨터 비전
- TensorFlow
- 골빈해커
- pytorch
- MFC 프로그래밍
- c언어
- 딥러닝 스터디
- 모두의 딥러닝
- 가우시안 필터링
- 파이토치
- 모두의 딥러닝 예제
- c언어 정리
- 딥러닝
- C언어 공부
- 케라스 정리
- 딥러닝 공부
- Pytorch Lecture
- 해리스 코너 검출
- 김성훈 교수님 PyTorch
- Today
- Total
ComputerVision Jack
PyTorch Lecture 10 : Basic CNN 본문
CNN
이번 시간엔 이미지 데이터에서 특징을 추출하여 학습을 진행하는 CNN 모델을 설명해주셨습니다.
cnn 모델은 convolution layer를 통해서 이미지의 feature을 추출하고 해달 추출된 모델을 분류기에 넣어 진행하는 방식입니다. 따라서 전 시간에 배운 MNIST 이미지 데이터에 대해 간단한 CNN 모델을 만들어 보겠습니다.
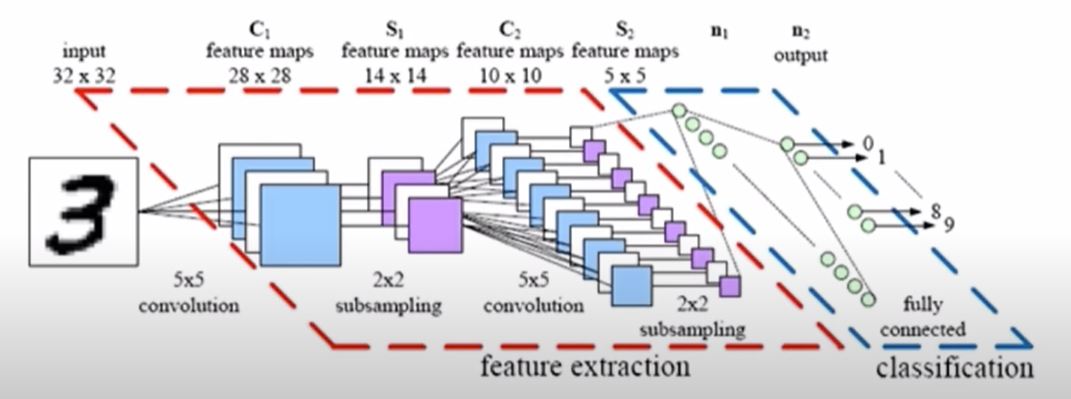
Simple convolution layer (stride : 1 x 1)
우선 컨볼루션 레이어의 연산에 대해 살펴보겠습니다. 이미지와 w(필터)가 곱 연산으로 진행됩니다.
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
위의 그림처럼 3 x 3 이미지가 존재하고 해당 이미지의 픽셀 값은 각각 1~9까지 존재한다고 생각하면됩니다.
여기에 2 x 2필터를 적용하여 layer를 추출해보겠습니다.
| 0.1 | 0.5 |
| 0.3 | 0.4 |
위의 그림은 이미지와 연산이 적용될 2 x 2 필터이며 해당 필터의 값은 위와 같습니다.
따라서 처음 이미지와 필터가 연산이되면
| 1 | 2 |
| 4 | 5 |
| 0.1 | 0.5 |
| 0.3 | 0.4 |
이렇게 두개의 식으로 연산이 진행되고 따라서 layer (1, 1)에 추출되는 값은 (1 x 0.1) + (2 x 0.5) + (4 x 03) + (5 x 0.4)가 됩니다. 다음 stride가 1이기 때문에 필터를 옆으로 이동시키는 간격이 1이됩니다. 즉
| 2 | 3 |
| 5 | 6 |
과 다음 필터가 만나서 연산을 진행한 값이 layer(1,2)의 값이 됩니다. 다음 방법으로 쭉 진행하다보면 해당 이미지와 필터 연산을 통해 (2 x 2 ) layer가 추출됩니다.
Stride
strdie는 간격을 의미합니다. 즉 이미지에 대해 필터 연산을 진행한 후, 해당 필터를 이미지의 다음 간격에 적용할 때, 그 정도 값을 의미합니다.
Padding
위의 연산을 참고하시면 해당 이미지는 (3 x 3) 사이즈 이며 필터 연산을 진행한 후, 추출되는 레이어는 (2 x 2) 사이즈입니다. 즉 (3 x 3) -> (2 x 2)로 사이즈가 감소된 것을 확인할 수 있습니다. 따라서 (3 x 3) - > (3 x 3)으로 만들고 싶기 때문에 이미지에 패딩을 진행합니다.
| 1 | 2 | 3 | 0 |
| 4 | 5 | 6 | 0 |
| 7 | 8 | 9 | 0 |
| 0 | 0 | 0 | 0 |
위와 같은 식으로 이미지에 패팅을 진행하고 필터 연산을 진행하면 추출된 레이어는 (3 x 3) 사이즈가 되는 것을 확인할 수 있습니다. 이를 통해 해당 이미지 데이터의 손실을 방지하고자 우리는 패딩 연산을 실행하는 것을 알 수 있습니다.
Max Pooling
max pooling 방식 같은 경우 해당 이미지에서 필터를 적용할 때, 최대 값을 취하는 방식입니다.
| 1 | 1 | 2 | 4 |
| 5 | 6 | 7 | 8 |
| 3 | 2 | 1 | 0 |
| 1 | 2 | 3 | 4 |
이런식으로 single depth slice가 있다고 생각해봅시다. 여기에 2 x 2 필터를 적용하는데, stride를 2로 정의하고 max pooling 방식을 도입한다면
| 6 | 8 |
| 3 | 4 |
가 됩니다. (1, 1, 5, 6) 중 최대값은 6이 되고, (2, 4, 7, 8) 중 최대값은 8이됩니다. 즉 이런 방식으로 진행하면 결과를 알 수 있습니다.
Locally Connected Features
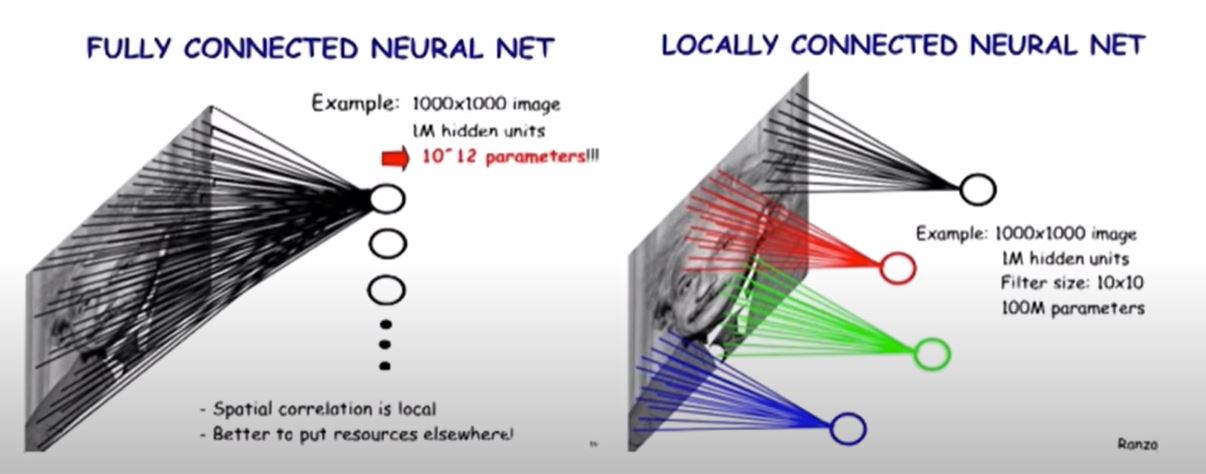
다음 경우 이미지 추출방식에 따른 방법입니다. fully connected 같은 경우 전체의 이미지에서 특징을 추출하여 사용합니다. 하지만 locally conneted 방식 같은 경우 해당 ROI 에 대해 이미지 특징을 추출합니다.
[10.Cnn_mnist]
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# 해당 실습에 필요한 파일을 import합니다.
batch_size = 64
# batch_size = 64로 설정합니다.
train_dataset = datasets.MNIST(root='./data/', train = True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/', train = False, transform = transforms.ToTensor())
# 전 시간과 마찬가지로 학습에 필요한 데이터셋과, 테스트에 필요한 데이터셋을 준비합니다.
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
#각각 데이터에 해당하는 loader를 만들어줍니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = F.relu(self.mp(self.conv2(x)))
x = x.view(in_size, -1) # flatten the tensor
x = self.fc(x)
return F.log_softmax(x)
#해당 cnn 네트워크를 생성합니다.
우선 Conv2d 1layer로 10개의 (24 x 24) 피처가 추출됩니다. 여기에 max pooling을 적용하면 10 (12 x 12) 입니다.
다음 Conv2d 2layer로 20개의 (8 x 8) 피처가 추출됩니다. 여기에 max pooling을 적용하면 20 (4 x 4) 입니다.
이제 flatten을 적용하면 (20 x 4 x 4) = 320 됩니다. 따라서 (320, 10)입니다.
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#객체 생성 후, 최적화를 진행합니다.
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#해당 모델에 대해 학습을 진행할 함수를 제작합니다. train_loader에서 학습 데이터를 읽어와 학습을 진행합니다.
def test():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target, size_average=False).data
# get the index of the max log-probability
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
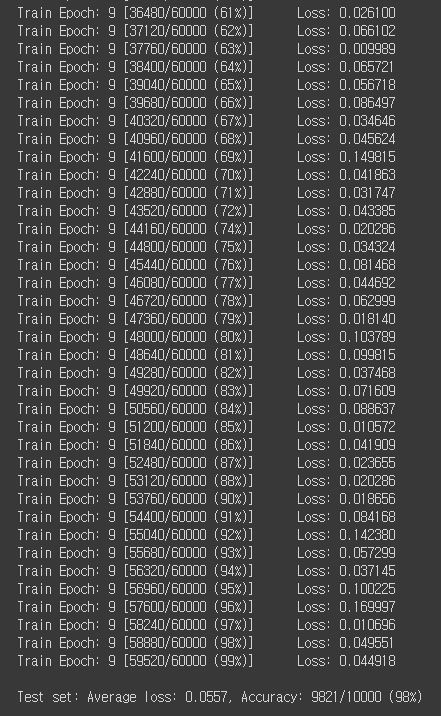
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
#해당 학습된 모델에 대해 test_loader에 존재하는 test data를 읽어와 적용합니다.
for epoch in range(1, 10):
train(epoch)
test()
'DeepLearning > Pytorch_ZeroToAll' 카테고리의 다른 글
| PyTorch Lecture 11 : Advanced CNN (0) | 2020.10.27 |
|---|---|
| PyTorch Lecture 09 : softmax Classifier (0) | 2020.10.23 |
| PyTorch Lecture 08 : DataLoader (0) | 2020.10.21 |
| PyTorch Lecture 07 : Wide and Deep (0) | 2020.10.20 |
| PyTorch Lecture 06 : Logistic Regression (0) | 2020.10.12 |



