
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 팀프로젝트
- Pytorch Lecture
- c언어 정리
- 영상처리
- 파이토치
- 컴퓨터 비전
- 모두의 딥러닝
- 골빈해커
- pytorch
- TensorFlow
- 딥러닝 공부
- c언어
- c++
- tensorflow 예제
- c++공부
- 딥러닝
- 해리스 코너 검출
- 가우시안 필터링
- C언어 공부
- 딥러닝 스터디
- matlab 영상처리
- MFC 프로그래밍
- object detection
- pytorch zero to all
- 파이토치 강의 정리
- 김성훈 교수님 PyTorch
- 파이토치 김성훈 교수님 강의 정리
- 케라스 정리
- 미디언 필터링
- 모두의 딥러닝 예제
Archives
- Today
- Total
ComputerVision Jack
Deep Residual Learning for Image Recognition 본문
Reading Paper/Classification Networks
Deep Residual Learning for Image Recognition
JackYoon 2021. 12. 20. 21:18반응형
Deep Residual Learning for Image Recognition
Abstract
- Network 구조를 이전과 달리 깊게 쌓아 학습을 쉽게 하려고
Residual Learning Framework발표한다. - 다른 기능들은 사용하지 않으며, Layer Input에
Learning Residual Functions적용하면서 Layer의 구조를 재구성하는 방법이다. - Depth (of Representations)는 많은 Visual Recognition Tasks에서 중요하다.
📌 Network의 Depth 늘릴 경우, Gradient Vanishing 문제가 발생한다. 따라서 깊게 쌓기 위한 방향성의 연구 토대가 되었다.
Introduction
- Deep Convolutional Neural Networks는 Image Classification에서 획기적인 흐름을 이끌어왔다.
- Deep Networks low/mid/high 단계의 Feature 통합한다. 그리고 Multi-Layer의 end-to-end의 Classifier는 널리 퍼지게 하며, 각 Feature의 "Level"은 Layer 깊게 쌓으면서 보강될 수 있다.
- 따라서 Depth는 중요하며, 결과를 이끈다.

- Depth의 중요성에 입각하여, "Network에 Layer 추가하는 방향이 더 좋은가? 에 대한 질문이 따라오게 된다.
- 이 질문에 답하기에 가장 큰 장애물은
Vanishing/Exploding Gradients문제이다. - 이 문제에 대해
normalized initialization및intermediate normalization layers10개 이상의 Layer 수렴하게 만들었다. - 그러나 Network가 깊어지면 정확도 하락 문제가 발생하였다. 이 하락은 Overfitting 인해 발생된 것은 아니다. 즉, Deep Model이 Shallower Model에 비해 높은 Training Error 발생시켰다.
- 해당 논문에서 Layer 직접적으로 쌓지 않고,
Residual Mapping이용한다.
$F(x) := H(x) - x$

- 해당 공식의 경우
Shortcut Conntection이해할 수 있다. 이는 하나 또는 여러 Layer 건너 뛴다. - 저자들은
Identiy Mapping이용하여 수행하였고, 이 output은 쌓여진 Layer에 더해진다.Identiy Shortcut Connection추가 Parameter가 필요하지 않고, Computation 또한 복잡하지 않다.
📌 **[ResNet 실험 결과]** 1. Depth가 증가할 수록 다른 Network는 Training Error가 높은 반면 Deep Residual Nets은 그렇지 않다. 2. Depth가 증가 해도 이전 Network에 비해 더 높은 정확도를 얻을 수 있다.
Deep Residual Learning
Residual Learning
- $H(x)$에서 x는 이러한 Layer의 Input 지칭한다. 따라서 H(x)에 유사하게 만드는 대신 F(x) := H(x) - x에 근접 시키도록 한다. 따라서 F(x) + x가 된다. 두 형태 모두 추정할 수 있어야 하지만, 학습의 용이성은 다를 수 있다.
- 만약 추가 Layer가
Identiy Mappings이용하여 설계된다면, Deep Model은 Shallower Model 보다 Training Error가 낮을 것이다. Optimal Function가 Zero Mapping 보다 Identity Mapping에 가까울 경우, Solver는 새로운 함수를 학습하는 것보다 Identity Mapping 수정하는 것이 더 쉬워야 한다.- Identity Mapping by Shorcuts
- $y = F(x, [w^i]) + x$ Building Block 다음과 같은 수식으로 정의할 수 있다. 해당 수식에서 x와 y는 input 및 output 지칭하고, F(x)는 Residual Mapping 학습 수식을 의미한다.
- $F = W2∂(W1x)$ ∂는
ReLU의미하고,bias는 생략된다. - F + x 연산은
Element - Wise Addition진행된다. - F와 x의
Dimensions이 다른 경우Linear Projection통해 Shortcut Connection 진행한다.
📌 Element-wise Addition 2개의 Feature map에서 Channel by Channel 진행
Network Architectures
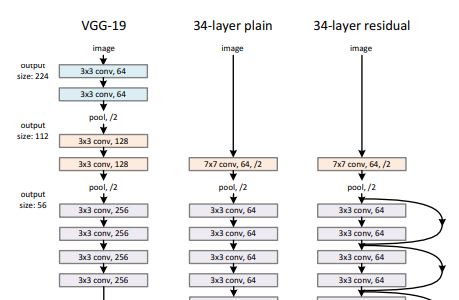
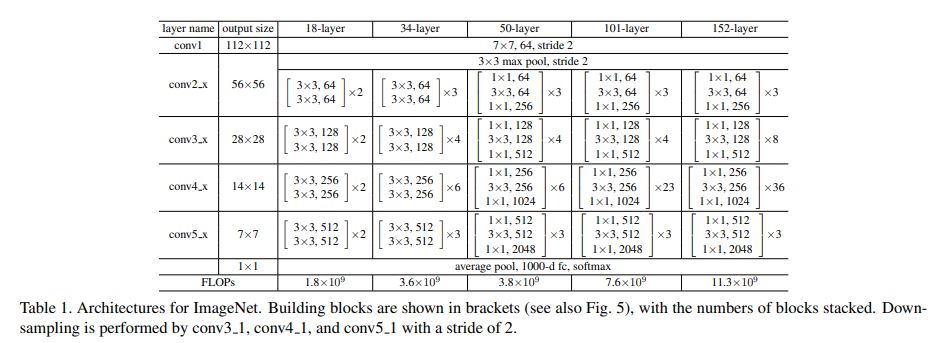
- ResNet (Residual Network) 구성하면서 2가지 Option 고려한다.
- Shortcut은 zero padded 하여 차원을 증가 시키며 수행된다. (Parameter 증가 없음)
- Dimension Maching 하기 위해 Projection 사용한다. (1 x 1 convolution)
📌 Skip Connection 구현할 경우, Stride = 2에 대한 부분에 대해 명시가 되어 있지 않다. 또한 input → 1 x 1 Convolution 진행할 때, Stride = 2 적용하자.
Experiments
Deeper Bottlenect Architectures
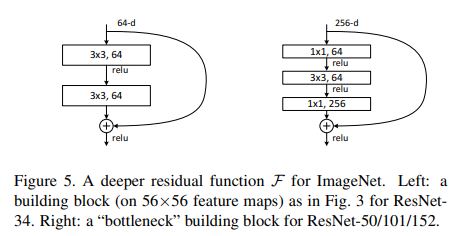
- Training-Time 인하여 Building Block →
BottleNeck디자인하였다. - 해당
1 x 1 Convolution차원을 줄이고 늘리는 기능만 담당한다. 일반 3 x 3 연산과 동일한 Complexity 갖는다. - BottleNect 이용하여 Identity Shortcut 효과적인 모델을 생성할 수 있다.
from ..layers.convolution import Conv2dBnAct, Conv2dBn
from ..initialize import weight_initialize
import torch
from torch import nn
class ResNetStem(nn.Module):
def __init__(self, in_channels, out_channels):
super(ResNetStem, self).__init__()
self.conv = Conv2dBnAct(in_channels=in_channels, out_channels=out_channels, kernel_size=7, stride=2)
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, input):
output = self.conv(input)
output = self.max_pool(output)
return output
class Residual_Block(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, stride=1):
super(Residual_Block, self).__init__()
self.out_channels = out_channels
self.res_conv1 = Conv2dBnAct(in_channels=in_channels, out_channels=in_channels, kernel_size=1, stride=1)
self.res_conv2 = Conv2dBnAct(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size, stride=1)
self.res_conv3 = Conv2dBn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride)
self.identity = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride)
# init memory consider
def forward(self, input):
output = self.res_conv1(input)
output = self.res_conv2(output)
output = self.res_conv3(output)
if input.size() != output.size():
input = self.identity(input)
output = input + output
return output
def get_channel(self):
return self.out_channels
class Make_Layers(nn.Module):
def __init__(self, layers_configs, pre_layer_ch):
super(Make_Layers, self).__init__()
self.pre_ch = pre_layer_ch
self.layers_configs = layers_configs
self.layer = self.residual_layer(self.layers_configs)
def forward(self, input):
return self.layer(input)
def residual_layer(self, cfg):
layers = []
input_ch = cfg[0]
for i in range(cfg[-1]):
if i == 0:
layer=Residual_Block(in_channels=self.pre_ch, kernel_size=cfg[1], out_channels=cfg[2], stride=cfg[3])
else:
layer = Residual_Block(in_channels=input_ch, kernel_size=cfg[1], out_channels=cfg[2])
layers.append(layer)
input_ch = layer.get_channel()
return nn.Sequential(*layers)
class _ResNet50(nn.Module):
def __init__(self, in_channels, classes):
super(_ResNet50, self).__init__()
self.resnetStem = ResNetStem(in_channels=in_channels, out_channels=64)
# configs : in_channels, kernel_size, out_channels, stride, iter_cnt
conv2_x = [64, 3, 256, 1, 3]
conv3_x = [128, 3, 512, 2, 4]
conv4_x = [256, 3, 1024, 2, 6]
conv5_x = [512, 3, 2048, 2, 3]
self.layer1 = Make_Layers(conv2_x, 64)
self.layer2 = Make_Layers(conv3_x, 256)
self.layer3 = Make_Layers(conv4_x, 512)
self.layer4 = Make_Layers(conv5_x, 1024)
self.classification = nn.Sequential(
Conv2dBnAct(in_channels=2048, out_channels=1280, kernel_size=1),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(1280, classes, 1)
)
def forward(self, input):
stem= self.resnetStem(input)
s1 = self.layer1(stem)
s2 = self.layer2(s1)
s3 = self.layer3(s2)
s4 = self.layer4(s3)
pred = self.classification(s4)
b, c, _, _ = pred.size()
pred = pred.view(b, c)
return {'pred':pred}
def ResNet(in_channels, classes=1000, varient=50):
if varient == 50:
model = _ResNet50(in_channels=in_channels, classes=classes)
else:
raise Exception('No Such models ResNet_{}'.format(varient))
weight_initialize(model)
return model
if __name__ == '__main__':
model = ResNet(in_channels=3, classes=1000, varient=50)
model(torch.rand(1, 3, 224, 224))반응형
'Reading Paper > Classification Networks' 카테고리의 다른 글
| Squuze-and-Excitation Networks (0) | 2021.12.28 |
|---|---|
| MobileNetV2: Inverted Residuals and Linear Bottlenecks (0) | 2021.12.24 |
| Densely Connected Convolutional Networks (0) | 2021.12.23 |
| MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (0) | 2021.12.22 |
| Aggregated Residual Transformations for Deep Neural Networks (0) | 2021.12.21 |
'Reading Paper/Classification Networks' Related Articles
more




Comments