
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- c언어 정리
- pytorch
- C언어 공부
- 딥러닝 공부
- 딥러닝
- c언어
- pytorch zero to all
- object detection
- 파이토치 강의 정리
- 모두의 딥러닝
- 딥러닝 스터디
- 김성훈 교수님 PyTorch
- 미디언 필터링
- 케라스 정리
- 가우시안 필터링
- 모두의 딥러닝 예제
- 컴퓨터 비전
- c++
- 영상처리
- 파이토치
- 골빈해커
- matlab 영상처리
- tensorflow 예제
- c++공부
- TensorFlow
- 해리스 코너 검출
- Pytorch Lecture
- 파이토치 김성훈 교수님 강의 정리
- MFC 프로그래밍
- 팀프로젝트
- Today
- Total
ComputerVision Jack
[모두의 딥러닝 Chapter03] 본문
[03-1 minimizing_cost_show_graph]
cost graph 확인해보기
import tensorflow as tf
import matplotlib.pyplot as plt
#tensorflow와 cost graph를 그려보기 위해 matplotlib 라이브러리를 import합니다.
X = [1, 2, 3]
Y = [1, 2, 3]
#x와 y데이터를 준비합니다.
W = tf.placeholder(tf.float32)
# bias는 고려하지 않고 weight만 신경쓰기로 하고, placeholder로 feed_dict으로 던저줄
공간을 생성합니다.
hypothesis = X * W
# Linear Regression 모델(가설) 설정합니다.
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# 오차의 제곱의 평균으로 cost함수를 제작합니다.
W_history = []
cost_history = []
#학습에 의해 변경될 weight과 cost를 담을 빈 리스트를 생성합니다.
with tf.Session() as sess:
for i in range(-30, 50):
curr_W = i * 0.1
curr_cost = sess.run(cost, feed_dict ={W: curr_W})
W_history.append(curr_W)
cost_history.append(curr_cost)
plt.plot(W_history, cost_history)
plt.show()
#학습을 시킵니다. 한번의 학습이 이루어 질때마다 그때의 weight값과 cost값을 list에 append시킵니다.
그리고 마지막에 plt.show()메소드를 사용해서 화면에 그래프를 보여줍니다.
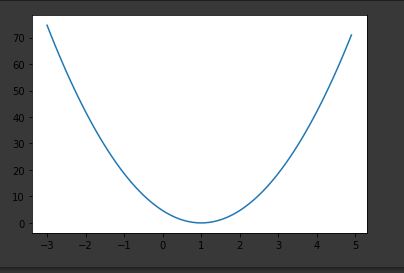
cost함수를 생각하시면 (오차 - 실제값)^2 이기 때문에 충분히 유도가 가능합니다.
[03-2 minimizing_cost_gradient_update]
Gradient Descent (경사 하강법)
경사 하강법은 실제의 수식을 그대로 코드로 번역하기만 하면됩니다.
03-2 예제는 03-1 코드와 많은 부분 유사한데 optimizer부분이 추가됩니다.
learning_rate = 0.01
gradient = tf.reduce_mean((W * X - Y) * X)
descent = W - learning_rate * gradient
update = W.assign(descent)
#optimizer = tf.train.GradientDescentOptimizer.minimize(cost)
위코드를 수학적으로 풀어서 설명해 놓은 코드입니다.
learning_rate에 전의 기울기를 계속해서 빼나가 감소시킵니다.
그리고 새롭게 W에 assign해서 W를 초기화 시킵니다.
[03-3 minimizing_cost_tf_optimizer]
학습 경과 보기
W = tf.Variable(5.0)
# W를 tf.random_norml()값으로 주지 않고 5.0상수로 초기화 시켜서
학습이 진행되는 동안에 올바르게 찾아가는지 보는 예제입니다.
[03-4 minimizing_cost_tf_gradient]
gradient(기울기) 조작이 필요할 경우
이 예제는 gradient에 개발자가 개입해 코드를 수정하고 싶은 경우, 필요한 예제 입니다.
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 0.01)
# optimizer를 설정합니다.
그래디언트를 수동으로 적용합니다.
gvs = optimizer.compute_gradients(cost)
#cost값의 gradient를 계산하여 가져옵니다.
apply_gradients = optimizer.apply_gradients(gvs)
#변화된 gradient 값을 내포합니다. 전 gradient 값에 의하여 영향을 받습니다.
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(101):
gradient_val, gvs_val, _ = sess.run([gradient, gvs, apply_gradients])
print(step, gradient_val, gvs_val)
#sess.run()하고 print()찍어보면 gvs는 현재의 gradient값을 가져오고
apply_gradients는 조작을 거친 적용될 gradient를 나타내는 것을 알 수 있습니다.
'DeepLearning > DL_ZeroToAll' 카테고리의 다른 글
| [모두의 딥러닝 Chapter07] (0) | 2020.01.19 |
|---|---|
| [모두의 딥러닝 Chapter06] (0) | 2020.01.17 |
| [모두의 딥러닝 Chapter05] (0) | 2020.01.16 |
| [모두의 딥러닝 Chapter04] (2) | 2020.01.15 |
| [모두의 딥러닝 Chapter02] (0) | 2020.01.13 |

