
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 모두의 딥러닝 예제
- 김성훈 교수님 PyTorch
- c언어
- 해리스 코너 검출
- MFC 프로그래밍
- 영상처리
- c++공부
- Pytorch Lecture
- 모두의 딥러닝
- 팀프로젝트
- matlab 영상처리
- 케라스 정리
- pytorch
- 파이토치 김성훈 교수님 강의 정리
- c언어 정리
- 파이토치 강의 정리
- 컴퓨터 비전
- tensorflow 예제
- c++
- 가우시안 필터링
- pytorch zero to all
- TensorFlow
- 딥러닝
- 미디언 필터링
- 파이토치
- object detection
- 딥러닝 스터디
- C언어 공부
- 딥러닝 공부
- 골빈해커
- Today
- Total
ComputerVision Jack
Focal Loss for Dense Object Detection 본문
Focal Loss for Dense Object Detection
Abstract

- 객체의 위치에 대한 가능성에 대해 regular, dense sampling 적용하는
one-stage detectors는 빠르고 간단하다. 하지만two-stage detectors의 정확도 측면에는 다가가지 못했다. - 앞의 이유 중 가장 큰 원인은 dense detectors 학습 시킬 때,
foreground와background간의class imbalance것을 발견했다. 이러한 원인을 해결하기 위해cross entropy loss수정하여 잘 분류된 예제에 대해선down-weights적용한다. - 새로운 Focal Loss는
hard examples집합에 초점을 두어 방대한negative집합이 학습 기간 동안 detector 압도할 수 없게 한다. 이런 효과적인 loss 검증하기 위해 RetinaNet 간단한 dense detector 설계하였다.
GitHub - facebookresearch/Detectron: FAIR's research platform for object detection research, implementing popular algorithms lik
FAIR's research platform for object detection research, implementing popular algorithms like Mask R-CNN and RetinaNet. - GitHub - facebookresearch/Detectron: FAIR's research platform for ob...
github.com
Introduction
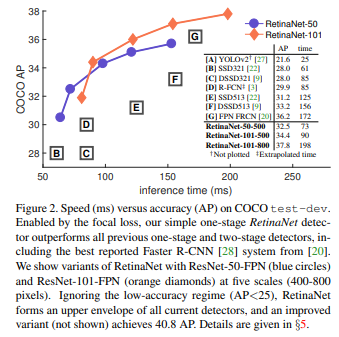
two-stage detector성공에도 불구하고, 자연적인 질문은one-stage detector또한 비슷한 정확도를 달성할 수 있지 않은가? 이다. 저자는 two-stage detector의 COCO AP와 일치하는 성능을 제시하는 one-stge detector 제시한다.- 이 결과를 달성하기 위해, 학습 시간 동안
class imbalance가 one-stage detector가 정확도 향상을 이루는데 주요 장애물인 것을 주장한다. 따라서 이러한 요소를 제거하기 위한 새로운loss제안한다. - one-stage detector는 image에서 추출된 object location에 대한 후보군의 집합에서 진행된다. 비슷하게 heuristics 특징이 적용된다고 하더라도, 학습 과정에서 쉽게 background 분류하기엔 충분하지 않다. 이런 불 충분함은 object detection의 고전적인 문제이다.
- 해당 논문에서 새로운
loss function제안한다. 이는 이전의class imbalance문제의 대안 보다 효과적인 방법이다. 손실 함수에서 동적으로cross entropy loss조절한다. 여기서 scaling factor는 제대로 예측한 class confidence가 증가하면 0으로 보낸다. - focal loss의 효과를 증명하기 위해 RetinaNet 간단한 one-stage detector 설계하였다. 이는 input image에서 object location 대해 dense sampling 한다.
Related Work
- RetinaNet의 설계는 이전의 dense detector와 비슷한 부분을 많이 공유한다. 특히 RPN에서 도입된
‘anchor’개념을 사용하며 SSD와 FPN에서 언급된 features pyramids 사용한다. 여기서 강조되는 점은 혁신적인 network design 아니라 간단한 설계로 새로운loss때문에 좋은 결과를 도출했다는 것이다. - class imbalance 2가지 문제를 야기한다.
- 대부분의
location정보가easy negatives이기 때문에 의미 있는 learning signal 제공하지 못하여 학습이 충분하지 않다. - 거대한 easy negatives가 학습을 압도하여 모델의 일반화를 막는다.
- 대부분의
- 따라서 제안한 focal loss는 one-stage에서 class imbalance 조작하여 sampling 없이 효율적으로 학습 시킬 수 있게 만든다. 또한 easy negative가 loss 압도하지 않아 gradient 계산할 수 있다.
outliers보기 보다 focal loss는inliers에게down-weighting적용하여 class imbalance 해결하려고 한다. 그래야 그들이 수가 많더라도 total loss에 기여하는 부분이 적다.
Focal Loss
- Focal loss는 학습 기간 동안
foreground와background불균형이 심한 one-stage object detection에 맞게 설계되었다. focal loss는 binary classification 위한cross entropy(CE)에서 시작되었다.

- (1) 수식에서 $y ∈ {±1}$ 은 ground-truth class 나타내고 $p ∈ [0, 1]$ 은 모델이 예측한 probability class 나타낸다. 편의를 위해 해당 수식은 (2) 바꿀 수 있다.
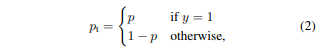
- 해당 loss의 주목할 만한 특징은 Figure 1 참고하면 된다. 쉽게 분류될 수 있는 예에 대해서 사소하지 않은 비중의 loss 발생 시킨다. 다수의 easy example 더할 때, 이러한 작은 loss 값들은 rare class에 대한 loss 압도할 수 있다.
Balanced Cross Entropy.
- class imbalance 해결하는 흔한 방법은 weight,
α ∈ [0, 1] factor도입하여 class 1에 적용하고 1-α 대해 -1 적용하는 것이다. α는 cross validation 동안 hyper parameter 다뤄진다.
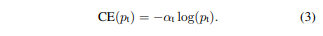
Focal Loss Definition.
- 쉽게 분류된
negatives는 다수의loss구성하고gradient지배한다.α-balances는positive/negative중요하지만easy/hard example은 차이가 없다. 따라서 loss function 새롭게 만들어 easy eample에down-weight적용하여hard negatives에 대해 중점을 둔다.

- focal loss는 2가지 이점이 있다.
- 잘못된 분류에 대해 $p_t$ 값은 작아지고 module값은 1에 가까워진다. 이는 loss에 영향을 미치지 않는다. $p_t$가 1이면 module은 0에 가까워지고 잘 분류된 예에는
down-weight적용한다. parameter γ통해서 easy example에 대해 down-weight 비율을 조절할 수 있다.
- 잘못된 분류에 대해 $p_t$ 값은 작아지고 module값은 1에 가까워진다. 이는 loss에 영향을 미치지 않는다. $p_t$가 1이면 module은 0에 가까워지고 잘 분류된 예에는
- 직관적으로 module factors는 easy example에 대한 loss 기여를 낮추고 낮은 loss 배정하는 경향이 있다.
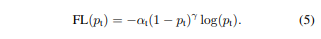
- loss layer가 sigmoid operation과 결합하여 p와 loss 함께 연산한다면 성능이 더 좋아지는 것을 확인했다.
Class Imbalance and Model Initialization
- 빈번한 class 때문에 loss는 전체 loss 지배하고, 초기 학습 시 불안정을 초래한다. 이를 해결하기 위해
‘prior’ = p개념을 도입하여 rare class(foreground) 평가한다.
Class Imbalance and Two-stage Detectors
- 제안한 focal loss는 two-stage의
cascade와minibatch참고하여 one-stage detection 시스템에 맞게 설계되었다.
RetinaNet Detector

- RetinaNet은
backbonenetwork와 2개의 task 위한subnetwork구성된 단일 통합 network이다. backbone은 전체 이미지에서 convolutional feature map 연산을 책임진다. 첫 번째 subnet은object의 classification진행하고, 두 번째 subnet은bounding box regression진행한다.
Feature Pyramid Network Backbone:
feature pyramid network(FPN) 가지고 ResNet 구조 상단에 설계하였다. pyramid 단계를 $P_3$에서 $P_7$까지 설정하였다. 또한 해당 pyramid channel = 256 통일 한다.
Anchors:
anchors는 $P_3(32^2)$에서 $P_7(512^2)$까지 각각 개별적인 구역을 갖는다. 각 pyramid level에서 3개의 비율(aspect ratios) 갖는 anchor{1 : 2:, 1 : 1, 2 : 1} 사용한다. 또한 3개의 크기(size) 갖는 anchor 사용한다.
각 anchor는 $K$의 길이 만큼 one-hot vector 할당 받는다. $K$는 class 개수 이며 나머지 4-vector는 box regression 정보이다. 뿐만 아니라 anchors에 ground-truth 배정할 때, intersection-over-union(IOU) 값이 0.5 이상인 정보만 사용하며 하나의 객체만 담당 할 수 있게 만든다.
Classification Subnet:
classification subnet은 각 $A$ anchors와 $K$ object class에 대해 객체의 존재 여부 가능성을 예측한다. subnet에 3 x 3 conv layer 적용하고, ReLU activation 할당한다. 마지막으로 output $K A$에 sigmoid activation 사용한다.
Box Regression Subnet:
각 pyramid 단계에서 작은 FCN 붙인다. 이를 통해 anchor box와 ground-truth 간의 offset에 대한 regression 진행한다.
Inference and Training
Inference:
inference 속도를 향상 시키기 위해, detector confidence 0.05 이상에 대해, FPN level에서 1k top-scoring prediction 부터 box prediction 진행한다. 모든 단계의 top predictions 통합되고, non-maimum suppression 통해 threshhold 값이 0.5 이상인 것만 최종적인 detection 산출된다.
Focal Loss:
classification subnet의 output에 focal loss 사용한다. γ = 2 값이 RetinaNet에서 효과적이며 강인한 것을 발견했다. image에 대해 최종 focal loss는 ground-truth box 정보가 nomalize된 많은 anchors에 대해 덧셈으로 진행된다.
Initialization:
RetinaNet의 subnet의 최종 layer 제외하고 모든 conv layers에 대해 bias=0, gausian weight σ=0.01 적용했다. classification subnet의 최종 layer에 대해 bias 값을 $b = -log((1-π)/π)$ 적용하였다.
Optimization:
RetinaNet은 stochastic gradient descent (SGD) 학습하였다. 학습 loss는 focal loss(classification)와 smooth L1 (regression) loss 더하여 진행된다.
Conclusion

- one-stage detectors가 two-stage detectors 처럼 수행하는 부분의 장애물이
class imbalance확인했다. - 따라서 cross entropy loss 수정한 새로운 focal loss 제안하고 이를 통해 학습하기 힘든
hard negative example에 중점을 두어 학습을 진행한다.
'Reading Paper > Object Detection' 카테고리의 다른 글
| Objects at Points (0) | 2022.04.14 |
|---|---|
| YOLOv3: An Incremental Improvement (0) | 2022.04.14 |
| Feature Pyramid Networks for Object Detection (0) | 2022.03.31 |
| YOLO 90000: Better, Faster, Stronger (0) | 2022.03.30 |
| SSD: Single Shot MultiBox Detector (0) | 2022.03.30 |



