
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 모두의 딥러닝 예제
- 딥러닝 스터디
- c언어 정리
- MFC 프로그래밍
- pytorch
- 가우시안 필터링
- 김성훈 교수님 PyTorch
- pytorch zero to all
- Pytorch Lecture
- c++공부
- C언어 공부
- c++
- 컴퓨터 비전
- 파이토치 강의 정리
- object detection
- matlab 영상처리
- 케라스 정리
- tensorflow 예제
- 딥러닝
- 팀프로젝트
- 해리스 코너 검출
- 딥러닝 공부
- TensorFlow
- 모두의 딥러닝
- c언어
- 영상처리
- 골빈해커
- 파이토치 김성훈 교수님 강의 정리
- 파이토치
- 미디언 필터링
Archives
- Today
- Total
ComputerVision Jack
[Vision Mask RCNN - Video] 본문
반응형
Mask R-CNN using colab
이번엔 사진이 아닌 동영상 파일에 대해 객체 검출을 진행하는 시간을 가졌습니다. 예전에 포스팅했던 Yolov5 모델 처럼 실시간으로 객체를 판별하는 것이 아닌 동영상을 읽어와 프레임 별로 나눈 후, 객체 검출을 진행하고, 마지막 부분에서 프레임을 재 취합하여 동영상을 만드는 방법입니다.

우선 videos 라는 디렉토리를 생성합니다. 다음 해당 디렉토리에 동영상 예제 파일을 다운받습니다.

명령어를 통해 해당 디렉토리에 다운받은 파일이 잘 있는지 확인합니다.

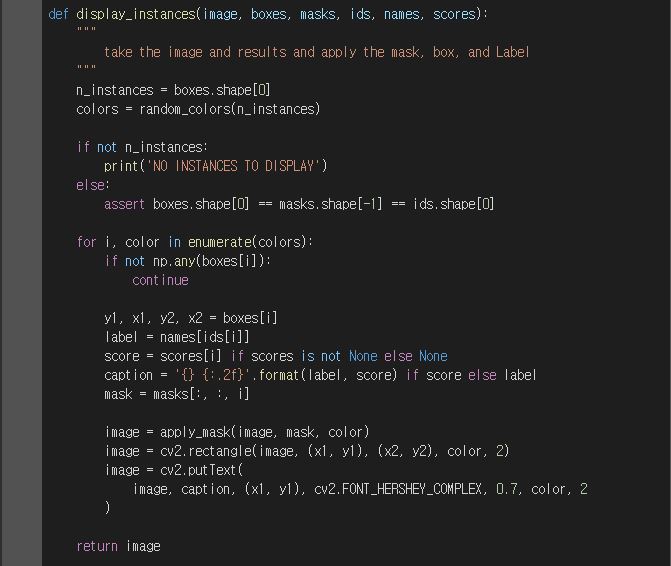
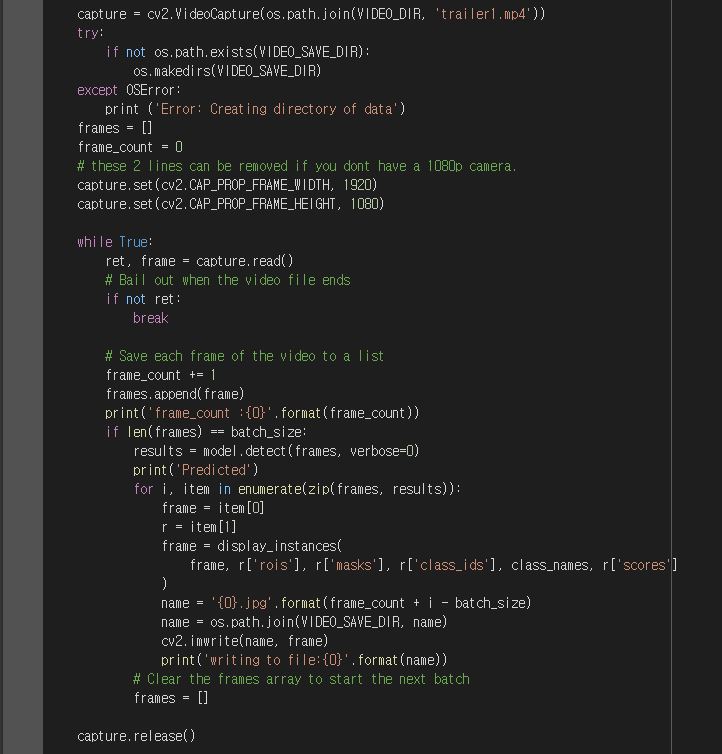
다음으로 환경과 재료 준비가 완료되었다면, cv2 라이브러리를 import 하여 VideoCapture 클래스를 사용해 동영상 파일을 frame 단위로 읽어 객체 검출을 진행합니다.
여기서 중요한 부분은 while True: 입니다. 우선 동영상의 frame을 더이상 읽어올 수 없을 때 까지 반복한 후, 해당 읽어온 frame에 대해 model.detect(frames, verbose = 0) 진행합니다.
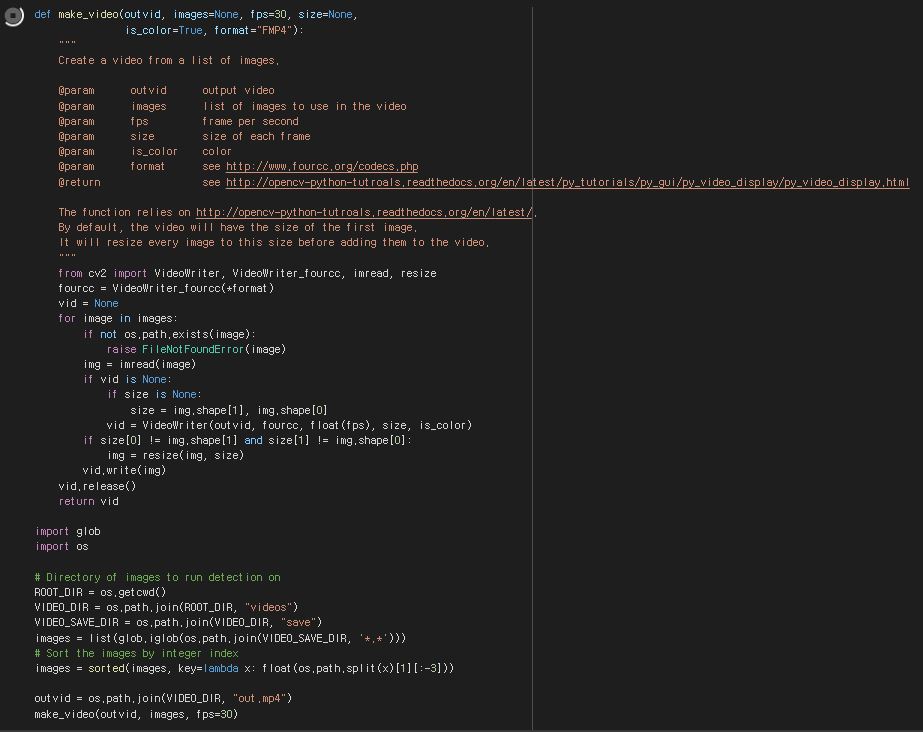
다음은 각각의 frame 이미지를 읽어와 객체 검출을 진행한 부분에 대해, 다시 취합하여 동영상으로 제작하는 함수 입니다.


해당 동영상을 다운받아 실행해 보시면 학습이 잘이뤄진 것을 확인할 수 있습니다.
반응형
'DeepLearning Study > Computer vision 스터디' 카테고리의 다른 글
| [Vision Mask RCNN - Image] (0) | 2020.10.19 |
|---|---|
| [vision Yolov5-Webcam] (16) | 2020.08.29 |
| [Vision Yolov5] (2) | 2020.08.21 |
'DeepLearning Study/Computer vision 스터디' Related Articles
more



Comments